In the 7 years since SimScale was founded, our software engineers have worked on a wide array of projects typical to web applications: basics like authentication or payment services, services for loading and storing different kinds of data into different storage services depending on size, cache-ability, integrations with other APIs, and so on. All of these, despite some of them proving tricky to get right for our use case, turned out to be a good match for one of AWS’ services which we use to run all of our compute and storage services.
However, as all of our software engineers will be able to confirm, SimScale operates in an application domain which is in many ways uniquely challenging—not just in learning application domain knowledge in and of itself, which is a process that now works well with computer scientists creating and running their own simulations, but in the fact that many of the workloads and associated technologies in our domain are not a natural fit to the cloud, or modern software engineering practices in general.
SimScale uses a variety of third-party software for actual simulations and for CAD and mesh processing and generation, which includes free and open-source software as well as commercial software. Common to virtually all of these software packages is that they have evolved over a long period of time, have a large number of contributors, are massive in size, complex in compilation and runtime requirements, and lastly not very amenable to the standardization of input and output formats. All of these factors are, let’s say, not catalysts for modern and agile methods of software development for complex systems.
At SimScale, most application-domain software we have encountered is written in its core or outer layers in C++. We have made the experience that while this choice can be reasonable, or at least understandable given the evolution of the code, we prefer other languages to build most of SimScale that we have found to be more productive in writing, debugging, and maintaining code; be it Java, Scala, Go or Node.js.
Additionally, on a fundamental architectural perspective, most existing simulation software packages combine all workflow steps from geometry processing, meshing, simulation, and post-processing into one application. Internally, the state of a simulation study can be kept in memory (at least in virtual memory) during the entire workflow, with forward-and-backward links between geometry, mesh, and results easily accessible at any time. While this requires often quite complex internal data structures, it also makes powerful features like locally refining a mesh to optimize results possible. On a related note, many of SimScale’s components requiring statefulness, sometimes for large data sets, is another challenge for development workflows, scalability, cost-efficiency, and snappy user experience.
Integrating Legacy Codebases
Elevating SimScale from its early prototypes into a mature software system and product required fundamentals like dockerizing all external components, creating internal data formats allowing, for example, referencing of model parts across the whole simulation workflow, creating standard input and output formats and translators and standardized mechanisms for collecting, analyzing and displaying debug and error information. Technology did not always provide significant leverage here—it was long, hard work consisting of design, experimentation, and development to get to a solid technological base.
One area where we did find game-changing leverage was in encapsulating C++ codebases. As mentioned before, prior experience with C++ codebases made us reluctant to extend 3rd-party C++ applications’ reach into our own services. Java, making up a significant part of our business logic, does offer JNI and JNA to interface with C++, neither of which seemed like an appealing option to us. Led by one of our senior developers, we started using Golang to interface with external C++ codebases and can now say this was an unequivocal success, making us much more productive, reducing maintenance efforts, and even allowing us to use modern stacks as we please.
Scalability and Pre-Warming
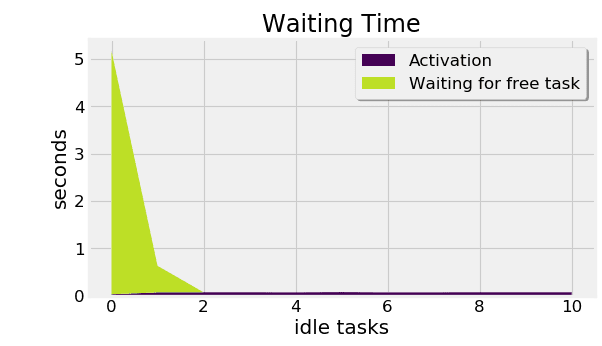
Despite our global userbase, we still observe varying patterns of load for the SimScale platform. Due to the fact that the jobs our users run have widely different resource requirements, scalability (both scaling up and down) is an essential requirement for both ensuring good performance and user experience, as well as cost-efficiency on our side. AWS EC2 is in principle a great match for this use case. However, as aforementioned, some of the software packages we need to run our jobs are large in size, leading to tens of gigabytes of docker images we need to execute jobs (not every job needing all of these, of course).

As described in the AWS documentation, storage volumes created from snapshots require data being loaded from S3 on first access. This led to unacceptable, and over time growing, delays in running jobs from the point of placing a job on an instance. We resolved this by maintaining an auto-scaling and auto-updating pool of pre-warmed storage volumes containing our docker images.
Another option would, of course, be to take a service-oriented approach and run the various applications making up our stack somewhere like ECS or EKS, and run jobs through a pipeline of those services. This approach is not a great fit for our workload due to the amount of data entering and being generated in a job run on SimScale, and the fact that some services need to operate on intermediate data while a job is still running.
Cost-Efficiency and Spot Instances
Beyond the software required to run a meshing or simulation job on SimScale, the jobs themselves also pose challenges. Especially because SimScale offers a free community plan, cost-efficiency is a priority for us. AWS’ spot instances are an easy way to achieve massive cost savings. In case you are not familiar with the concept, the short version is that AWS offers unused instance capacity at a discount, with the risk factor that if someone else is willing to pay more than you for this capacity, your instances might get terminated and reallocated (but not charged of course). This is not a big issue for workloads that can be easily split up and partially retried in case of failures or workloads that are not time-critical.
As you might imagine, SimScale’s workloads, being both long-running (with jobs lasting sometimes many days) and data-intensive, they are not a natural match for these constraints. The mechanism we have developed to handle this mismatch range in sophistication and are partly orthogonal:
- Retrying jobs on more expensive and stable instances (e.g., “on-demand” instances) in case an instance gets terminated.
- Flexible translation of job requirements (mainly CPU and RAM) to matching instance types, combined with adaptive blacklisting of instance types with frequent recent terminations, to reduce and distribute risk (spot terminations often only affect one or a few instance types).
- Safepoints/snapshots of job state, to be able to continue after a termination—this is much trickier than it sounds since it depends on the software supporting resuming from a saved state, something not commonly supported.
- Spreading our workload across multiple AWS regions to compete in a larger spot instance market—this involves tricky trade-offs because of added cost either for data transfer from the compute to processing and storage regions, or for running processing and storage services in multiple regions.
In case you missed it, AWS recently released a feature that makes working with spot instance capacity shortages much easier—capacity-optimized allocation strategy. To provide some context: AWS does publish the spot price history for all instance types, and in the past this provided at least a hint regarding contention for each instance type, allowing us to pick instance types that seemed to offer enough spare capacity to avoid terminations. Unfortunately, terminations are increasingly also happening due to lack of capacity not reflected in price increases, so this has become a bit less transparent and predictable. The new allocation strategy allows you to leverage AWS’ insider information on the available spot instance capacity.
Managing State
To move from quite internal to work that is closer to direct user impact: recently, we have also made significant, wow-inducing progress in the area of managing state. For some of the simulation workflow on SimScale, the snappiness of user experiences is not always of utmost importance—a simulation that runs days need not deliver results within seconds. In some areas, this snappiness is, however, rightfully expected.
One such area is in the preparation stage of a simulation, specifically when working with CAD geometries. While we do expect users to bring a CAD model to SimScale, often minor modifications are needed to make a model fully ready to go through meshing and simulation. Most of those modifications are very fast in the users’ CAD software, but the process of making a model ready can be iterative, and modifying a CAD model locally and re-uploading it to SimScale requires redoing some parts of the meshing or simulation setup—this can be very frustrating for our users.
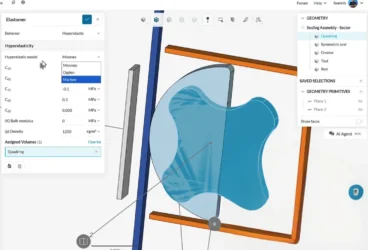
To alleviate this pain point, we have invested some time into developing an online, in-browser, CAD editing tool. It is based on the same library as our other internal CAD services, and like many libraries we use, was intended to hold state in memory while a user’s session is still active. Obviously, this again does not quite fit our ideal world of cloud services that are either stateless or can easily store and recall their state from a database or cache, having effects on our ability to right-scale this service and offer good UX while being cost-efficient. With some dedicated effort, we managed to implement state management for this service ourselves, and now have the ability to restore sessions within seconds—more or less the same as opening a file in traditional CAD software (as depicted above).
Conclusion
Over the years, we have accumulated many innovations that make us internally proud and externally the rightful leader in cloud-based simulation. However, challenges never cease to occur—we have found that many of our components have potential for optimization, and these opportunities only reveal themselves upon closer inspection, warranting improvements to our analytics pipeline. We still find ourselves with workloads that are not easily decomposable, making them expensive to run especially in case of interruptions, and making short delivery cycles a bit tricky. Finally, handling our increasingly complex data model will always be a topic, task, and moving target that keeps us busy.
If you want to join the leader in the world-changing move of simulation software to the cloud and add more innovations to this list that ensure that every product designer out there has access to simulation technology, head over to www.simscale.com/jobs!
Want to learn more about SimScale? Check out our resources below:
- About SimScale
- SimScale Careers Page
- Life at SimScale Video
- AWS Customer Success Story – SimScale
- Life at SimScale Instagram