In this article, we break down our 8 engineering teams that, together, work to make high-fidelity engineering simulation technically and economically accessible, at any scale, in the cloud.
Workbench Team
The Workbench team is responsible for the front-end piece of SimScale’s application. We work closely with all teams to connect all of SimScale’s functionalities to our browser-based application. We work with the latest technologies to ensure a great performance and user experience, from model management and simplification to simulation setup and result visualization.
Our team is always working on new ways to scale our application. We invest a lot of our time looking into the future of web development so we can keep adding features into a highly complex tool.

“I like that SimScale combines the direct communication and fast, valuable changes of startups with a corporate-minded approach to quality and tools. And, it’s a delight to be surrounded by professionals you trust and who trust you.”
— Daria Guketleva, Frontend Developer
Platform Team
Platform is the engine room for SimScale: we develop and operate those critical software components which provide the fundamentals for the rest of the engineering teams and the company. As we are responsible for scalability, both in the computational sense and the functional perspective, it’s a great challenge and a lot of fun at the same time. Gradually refining a microservice architecture with an ever-growing functionality is something that keeps the mind inspired and busy all the time for a software engineer. Last but not least, it’s a pleasure to work with so many engineers —including other teams and our customers, too— and continuously learn and solve real-world problems on a daily basis.

“For me, being a part of the Platform Team is such a great career opportunity. Not only am I getting to know and work side-by-side with talented and hard-working individuals, but I am contributing to an amazing product with a lot of challenges and state-of-the-art technologies. It is truly rewarding!”
— Daniel Plucenio, Software Engineer
CAD Team
The CAD team is responsible for everything related to CAD (computer-aided design) at SimScale. We split the responsibilities into three main areas:
First, each SimScale user starts by uploading a CAD model to SimScale. We are responsible for the upload success rate. Our users upload 7,000 CAD models per week and we continuously achieve a 90% upload success rate.
The second area of our work is CAD mode. This is our CAD editing tool which enables users to modify and simplify the models so that the simulations are faster and more successful. Here we typically implement new geometry operations based on Parasolid —our main geometry kernel. Our users perform around 5000 different CAD operations per week.
Our third task is to continuously improve and provide new CAD features required for simulation to make handling CAD more convenient for our users.
When working on the CAD team at SimScale, you benefit from:
- Working with different CAD models
- Working with new technologies (cloud, continuous release/testing, Go)
- Moving fast and with agility to meet market needs.
- Working together with a very diverse group of smart people (each member of our CAD team has a different nationality).
Meshing Team
Meshing sits between CAD and simulation, so we need to understand both sides very well. The mesh directly defines the structure of the matrix in the simulation, so the impact of a good mesh is huge. It can make the difference between a good, converged result, and a diverging solution. Some call meshing an “art”.
Our job is to get a convergent mesh done for each and every CAD, no matter which system it was created in, which shape it describes, or how poor its definition is.
Cloud-native meshing has never been done before, so we cannot copy from a textbook. We have to invent new solutions every day.
The cloud allows us to do things better than ever before. Thanks to continuous integration, we can find bugs early. Using a centralized logging and alerting system, we know immediately when one of our users struggles to get a mesh done. We are very proactive in finding and fixing bugs and over time, things are getting more robust. With continuous deployment, we can ship these improvements at any time, and our users can benefit immediately.

Structural Team
The Structural team keeps the structural analysis brain of SimScale alive, functional, and up-to-date. That brain has to process around 1000 jobs a week ranging from static, dynamic, and thermal analyses to frequency and harmonic simulations. Aligned with the company’s goal we aim to deliver cloud-native structural analysis solvers to make simulation truly accessible from everywhere, and at any scale. Our users come from different backgrounds and have different structural problems to solve. The challenge and fun part of our job is therefore to develop a tool that can handle all these problems on the cloud. A tool that is reliable, robust, validated, and as user-friendly as possible. To deliver that we develop our own in-house algorithms as well as provide adapters to different simulation engines.
In our daily work, we require a deep understanding of computational mechanics and computer science. Being on the cloud and practicing an agile mindset means that we must continuously improve our tool and continuously release the development to production —on a weekly. To make all that possible we detect bugs as early as possible and validate our developments before it reaches our users. To this end, we have several integration/validation tests in place (the number is increasing continuously) and our production pipeline runs those tests before every release. It is safe to say that we follow a “validation-driven-development” paradigm.
CFD Team
The CFD team essentially has two jobs: the “number crunching” and the “adapter” part, which makes our job extremely interesting. The number-crunching part relates to the fact that we develop our own CFD solutions to meet the needs of our current and future clients. Everyone who has spent time developing a CFD solver knows that making it user-friendly and robust is a challenge: there are so many controls in a simulation that may give poor results. The second, “adapter” part, is where “old-school” CFD development meets modern-day computer science.
The fact that we’re the first cloud-native CFD simulation platform brings fun challenges and means we learn a lot about software development best practices. In contrast to desktop-based CFD software where the release cycle is usually once a year, we release our components once a week. Therefore, the feature you’re working on today might be in the users’ hands in a week or so. In order to support such an agile development cycle, we have an extensive and automated testing and validation pipeline and really live the “validation-driven-development” paradigm.
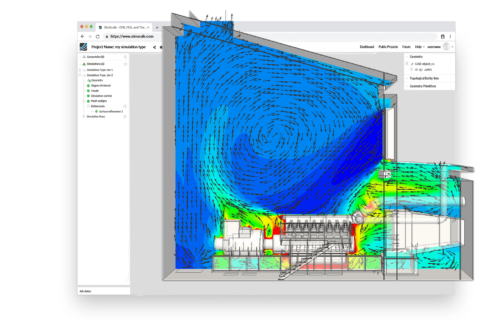
Our users are running around 1000 to 1500 jobs a day, which means that every error or simulation-related problem eventually surfaces. Because of this large data set, we get to learn new things about simulation and reveal new patterns in unprecedented ways.

“What I like the most about working in the CFD Team is the fact that I can work on two topics that I have always been interested in: physics and coding. On top of that, knowing that my work will allow users to design and build many useful applications makes the job in the team particularly rewarding.”
— Dante De Santis, Senior CFD Software Developer
Post-Processing Team
The Post-Processing team’s main concern is helping users understand and interpret their results. We achieve this by providing mechanisms to:
- Visualize results and meshes, by mapping different color schemes to physical quantity values (e.g. Velocity, Pressure) on the discretized model, either native or interpolated
- Visualize mesh divisions and feature edges
- Visualize flow characteristics, by means of vector glyphs or particle traces and particle trace animations
- Understand how the model evolves in time, with the help of animations applied on the 3D view
- Get a quantitative understanding of the results by providing entity value statistics as well as point probing
- Investigate the results by applying different operations, such as slicing, cutting, extracting a subset of values, establishing ranges, etc
Due to the particularities of the domain and tools we operate as a small, full-stack team. We are responsible for:
- The integration of the libraries from our technical partners for result data processing and visualization
- Designing, developing, maintaining, and monitoring post-processing related front-end and back-end functionality and components as well as some of the infrastructure, within the team, as well as in collaboration with other teams in the company
- Continuously ensuring correctness and improving our code base as well as fixing issues that arise, whenever possible before they affect our users
- Offering an ever-improving user experience, ease of use and performance for Simscale users (we have many simultaneous sessions, and on average, over tens of thousands of different simulation durations and sizes per week). Our cloud-native business model helps us make sure all of this reaches all of our users via frequent releases.
Machine Learning Team
The Machine Learning team is one of our newest departments, responsible for our machine learning efforts. We focus on three goals: making things easier for our users, reducing simulation costs, and increasing simulation speed.
SimScale is both a cloud software provider and a simulation tool—both of which carry implications for our job. Being a cloud software provider has its perks for a Machine Learning Team: we have a lot of data. We are responsible for the architecture that makes that data accessible and exploitable by machine learning algorithms (and by dashboarding tools, as well).
Being a simulation tool comes with its own challenges: the data we have to deal with is not standard for machine learning (think CAD drawings, meshes, simulation results, etc). The challenge is an opportunity to do exciting things and try new algorithms. As this is a greenfield, we feel limited only by our imagination.
Eventually, we want to disrupt how simulations are done: rather than using partial differential equations, we could have a (much) faster data-driven algorithm driving simulation. But before we get to that, we focus on the challenges at hand. For every operation the user does in “the cloud”, we want to use computing resources efficiently, which means selecting the right instance to run the job and predicting how much time it will take. The more we improve this process, the more confidence our users will have, the more simulations they’ll run, the more data we will collect, and the more fun we’ll have.
Stay tuned for more insights into SimScale and see what the team has been up to on our @lifeatsimscale Instagram feed. Want to start your own SimScale story? Make sure to keep an eye on our careers page for possible openings!





