AI’s transformative impact on engineering simulation is no longer a distant promise—it’s happening right before our eyes. Yet, while headlines often focus on advances in hardware and machine learning architectures, an elephant lurks in the room.
For engineering applications of AI, this metaphorical elephant is a tough one to dodge.
It is, of course, data – the lifeblood of any AI model.
Let’s take a step back and understand why.
We’ll see what can be learnt from other AI applications and look at how leading innovators are solving this bottleneck in the engineering space.
Lessons from LLMs: Data is the Determining Factor
The meteoric rise of LLMs like GPT, Gemini, and Claude is often attributed to exponential growth in computing resources and model size. These advances, however, only tell part of the story. These leaps in performance have been accompanied by a corresponding revolution in data engineering.
The extensive pre-training phase of LLM development requires meticulously curating, cleaning, deduplicating, and sequencing trillions of diverse text tokens to maximize learning efficiency and resulting model performance.
In the same way we have to be careful about what we say and how we behave in front of our children, we have to be careful about what makes it into training data sets.
Although the leading AI companies are understandably cagey about exactly how much time and effort (and precisely what) goes into the pre-training phase of model development, the accepted wisdom in the world of data science is that 80% of time and effort goes into data collection and preprocessing, with only 20% spent on modeling. So that’s a lot!
To summarize, the old adage that has been echoing around modeling and simulation teams for decades holds as true today as it ever did:
“Garbage in, garbage out”
Every wise simulation engineer, ever
In engineering simulation, where data is sparse, high-fidelity, and distributed, these lessons are especially relevant. AI systems are only as good as the data they ingest, and they need data quality over quantity.
But what does this mean for physics-based simulations, with their multidimensional numerical fields and complex geometric constraints?
You may, or may not, be sitting on a goldmine of data
All engineering organizations have data, most likely too much data!
Whether that data can be directly used to train useful AI models is another question entirely.
In a recent industry survey, we asked engineering companies about the blockers they encounter when trying to implement AI simulation workflows.
Difficulties in accessing and using data was the top concern raised!
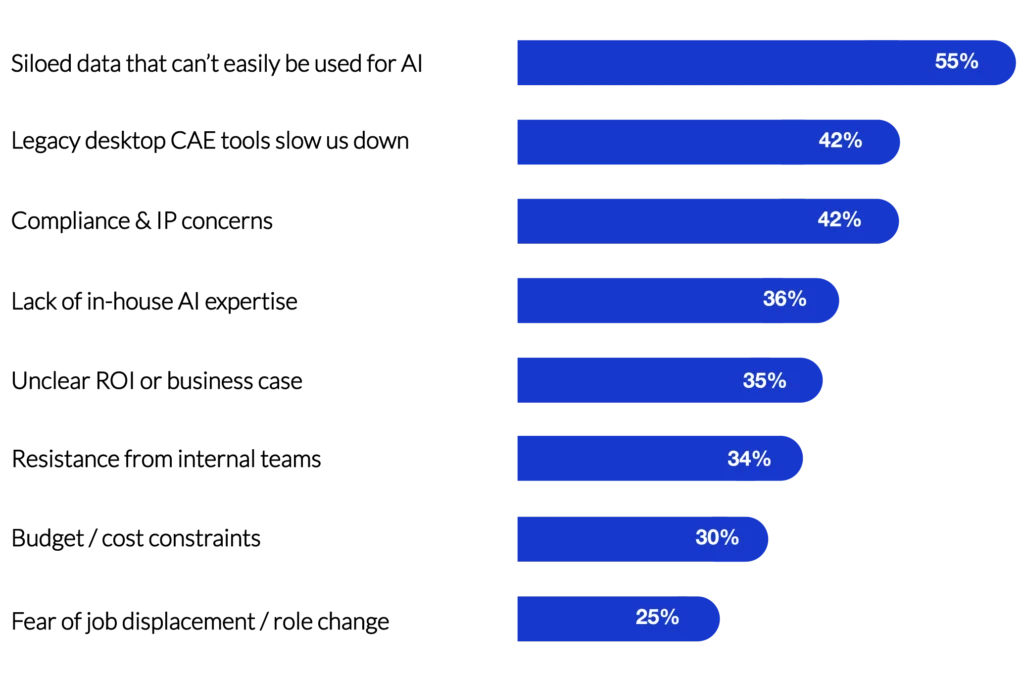
Why is engineering data so often siloed?
Engineering simulation starts with a new design candidate and/or a set of boundary conditions to investigate. It ends with an evaluation of some pre-determined KPIs that tell you how well the design performed with respect to your initial requirements.
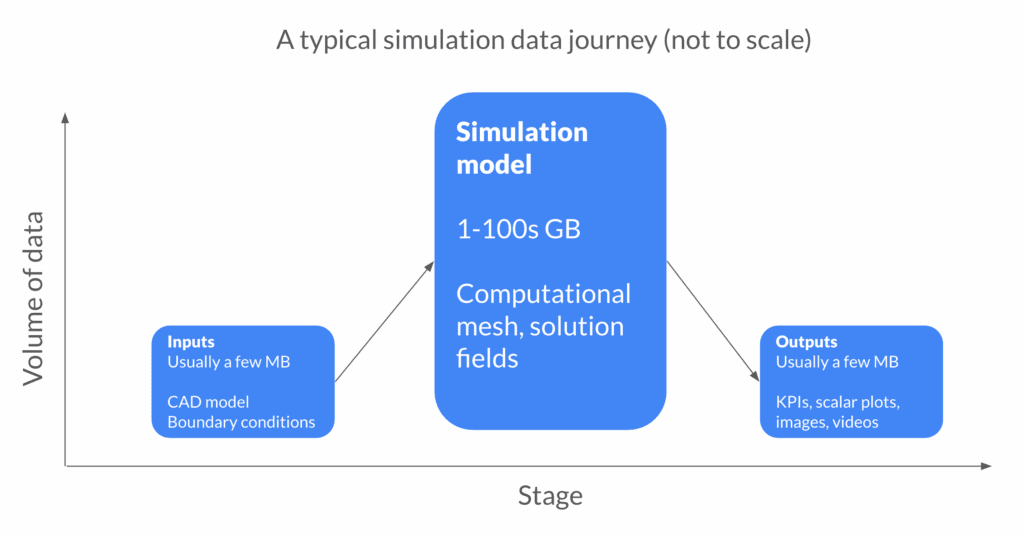
Considering the relative sizes of these puzzle pieces, there is a strong argument for discarding the model itself. After all, it can always be re-run if you really need it again… provided you have a good record of what the inputs were.
WARNING: This is a ‘pre-AI’ way of thinking.
The problem with this way of working is that the data that does get systematically retained is not at all AI-ready.
It might be usable for relatively simplistic forms of regression analysis, but it does not usually include the geometric inputs and full field outputs needed to train GNN or PINN models.
The data you really need is now fragmented over many systems, if it still exists at all. Maybe a PLM environment holds the CAD data archive, while KPIs and post processing images might be stored in another database, or maybe even a spreadsheet or folder structure on a shared drive.
Any given simulation model could be languishing on an external storage drive or cluster filesystem, or perhaps it was deleted to save space during a recent de-cluttering exercise. Who knows? It will certainly be a lot of work to find out, gather all the data together, and fill in the blanks.
The reality of legacy tools: a data nightmare
The situation I describe above is often the result when simulation software is used without a data management system in place—something very few teams have (only 5% in a 2019 survey). Legacy tools (whether run on-premises or in the cloud) leave a trail of files and folders behind them that need to be gathered up and archived either manually or using another tool to do the same automatically. Either way, order does not come easily.
Fragmentation of data stifles any attempt to automate data pipelines or scale AI deployment. The time and manpower required just to compile, validate, and align datasets quickly exceeds the cost of actual model training. The result is a cycle – AI pilots thrashed by unresolved data engineering workloads, and promising projects failing to leave the lab.
Cloud-native simulation includes built-in data management
Contrast this with a vertically integrated cloud simulation stack like SimScale. All simulation data generated on the SimScale platform persists (unless deleted) and remains organised and ready for further use or reuse. A single, cloud-native repository aggregates past and current projects, auto-tagged by discipline, physics, and defining parameters. Built-in AI infrastructure then directly taps into this data store, meaning that there are no obstacles to be navigated in between data generation and model training.
SimScale’s Physics AI model training dashboard provides complete control over model publication, versioning and sharing between users and teams. The same framework allows users to access pre-trained foundation models and incorporate them into AI-driven workflows.
What a data goldmine looks like: A real-world example
We recently collaborated with Nantoo, one of our customers designing garden power tools, to see whether the simulation data they had generated over a lengthy product development process could actually be directly used for AI model training. The interesting thing about this particular experiment was that the data had originally been generated with no future intention to use it for AI model training.
In this case we took the simulation runs as they were, without modification, and were able to quickly train a model using SimScale’s built in Physics AI. The results were impressive, and really show how using a cloud-native platform gives you a massive boost when getting AI adoption off the ground.
Why was the process so straightforward? The Nantoo team have been running simulations on SimScale for a while now, so they have built up a large library of runs, and SimScale saves all of your simulation data in the cloud – neatly organised into projects and analyses. They had also followed good practices like consistent model setup and orientation, naming conventions, and the like.
Since the data was in the cloud and ready to go, all that was needed was for the Nantoo team to share the relevant projects with us (a matter of a just few mouse clicks) and we could immediately create a copy of the project, dive into the data and start model training using SimScale’s built-in AI infrastructure.
Nantoo’s experience illustrates the transformative potential of this technology when deployed in a cloud-native environment. The key: centralized, structured data access and full traceability—capabilities supported by SimScale’s web-native, cloud-based infrastructure. By default, SimScale customers bypass much of the chaotic data wrangling endemic to on-premise tools and are positioned to unlock AI at pace.
Checklist: How to future-proof your data
Now is the moment to audit your simulation data landscape and take strategic action. The companies making the leap to AI-enabled engineering are those who treat data not as an afterthought, but as a first-class product. Take your initial step by evaluating your digital infrastructure—where does your data live, and how quickly can you put it to work? The future of engineering simulation belongs to those who master data, from preprocessing to deployment:
Quality
This is where the biggest parallels to LLM development can be drawn. The quality of a model’s predictions are directly related to the quality of the input data. This should cover many aspects, including mesh quality and model convergence.
Consistency
Because machine learning models are learning patterns between inputs and outputs, that data must be consistently structured, for example using the same flow direction and model orientation, and the same topology and boundary condition types. If you need to predict a specific scalar field, KPI or integral value, that data must already be present in each input run.
Accessibility
Model training requires ready access to the data. If it is scattered and fragmented, this will not only be a huge time sink to gather it together but it will also be very difficult to ensure 1) Quality and 2) Consistency. The simulation, data and model training environments need to be tightly integrated.
Ready to roll?
Identify one simulation process with accessible, high-integrity data, and commit to piloting your first AI-driven workflow—powered by a cloud-native, AI-native stack. The path to transformative innovation begins with your data.