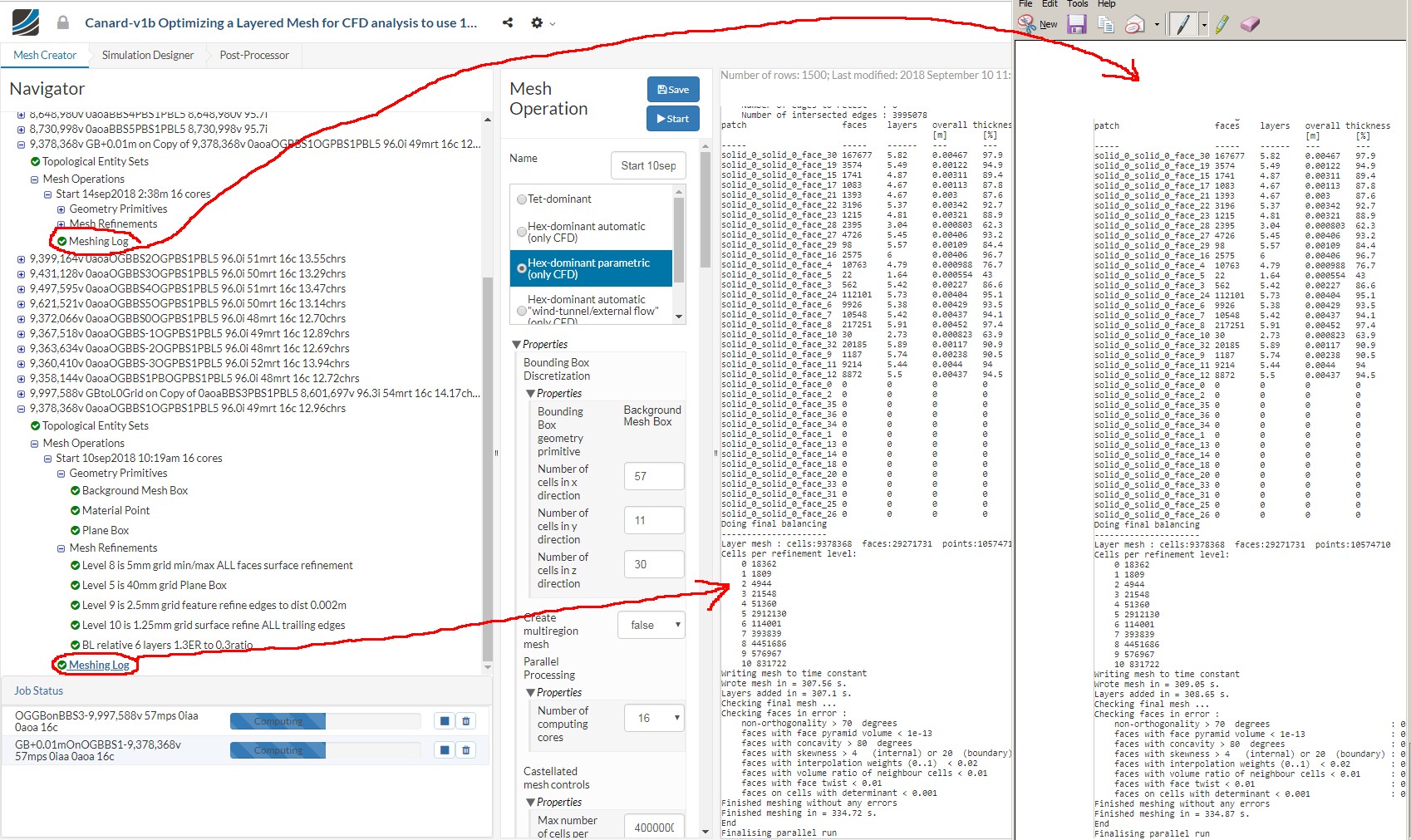
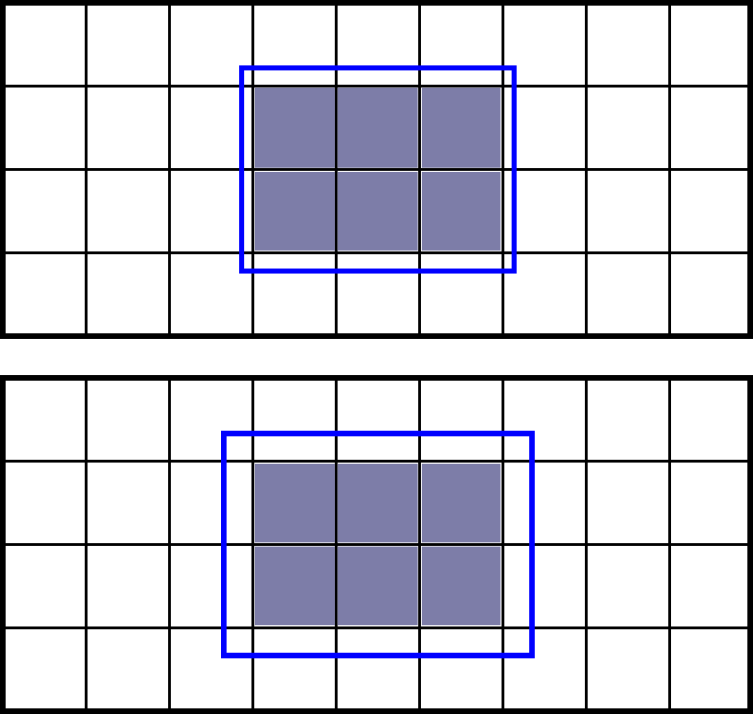
I have noticed that if I re-mesh an existing Hex-dominant parametric mesh with exactly the same parameters I end up with a mesh that has a different number of cells and faces than the original.
I re-meshed an 8.5 million cell mesh 7 times and the range of number of cells for the 8 meshes was about 16,000 cells.
All meshes were meshed with default parameter values and a 1.28 meter cell grid on the background mesh box.
The geometry was a complete aircraft and was refined and layered nicely to a yPlus of 50.
The background mesh box was significantly larger than the first region refinement box.
All meshes had 0 illegal cells but they all failed the OpenFoam quality check as ‘Mesh quality check failed. The mesh is not OK.’
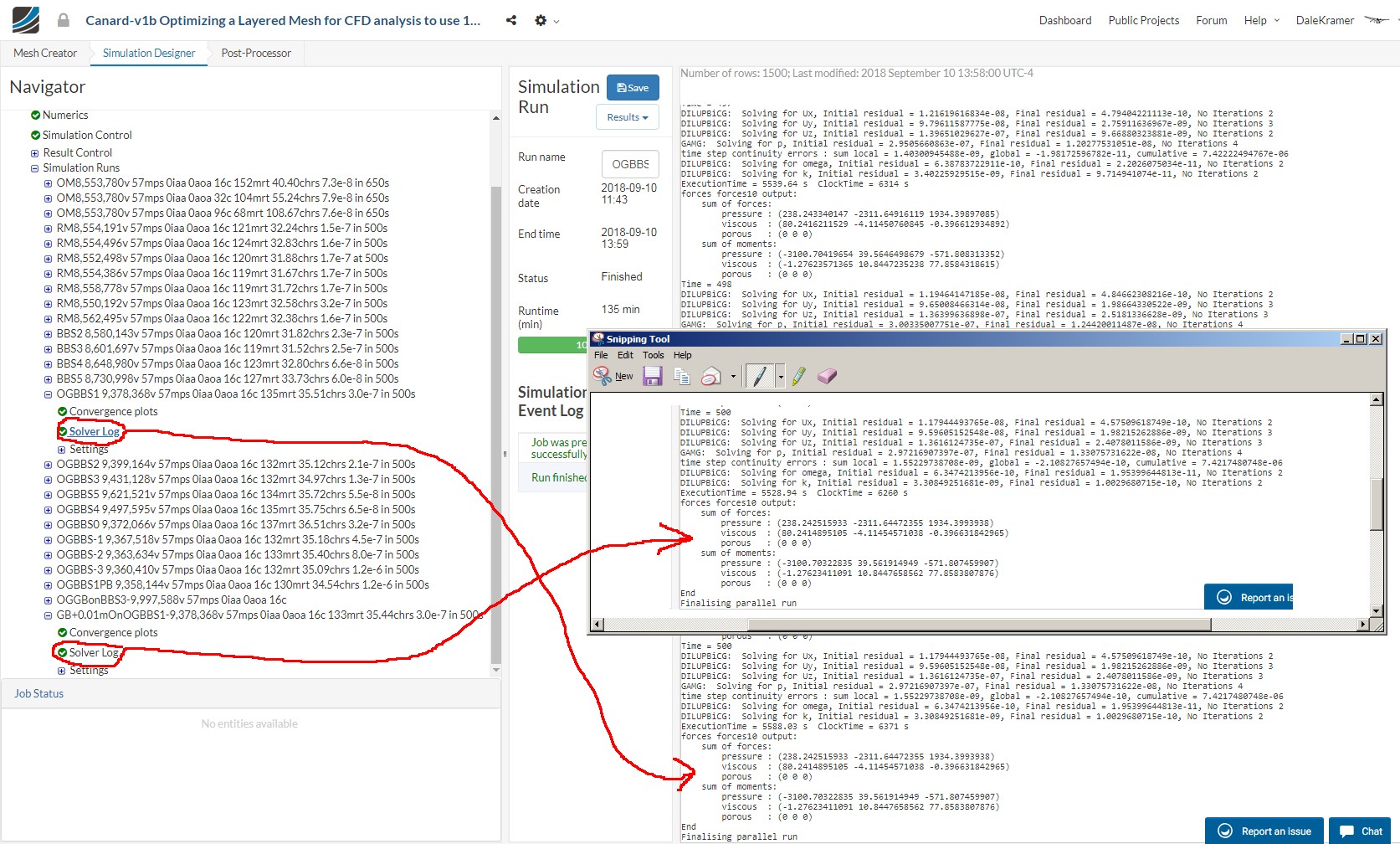
The fact that all these meshes are not the same number of cells concerned me enough to run them all through an incompressible steady state simulation and make a chart of the results variations.
Here is the results chart for all 8 sim runs:

Basically and with some relief, I found that for my situation all the meshes produced virtually the same results.
I present this forum topic for a discussion thread about whether this meshing anomaly could have any other significance or could it affect results in a way I have not foreseen.
Dale
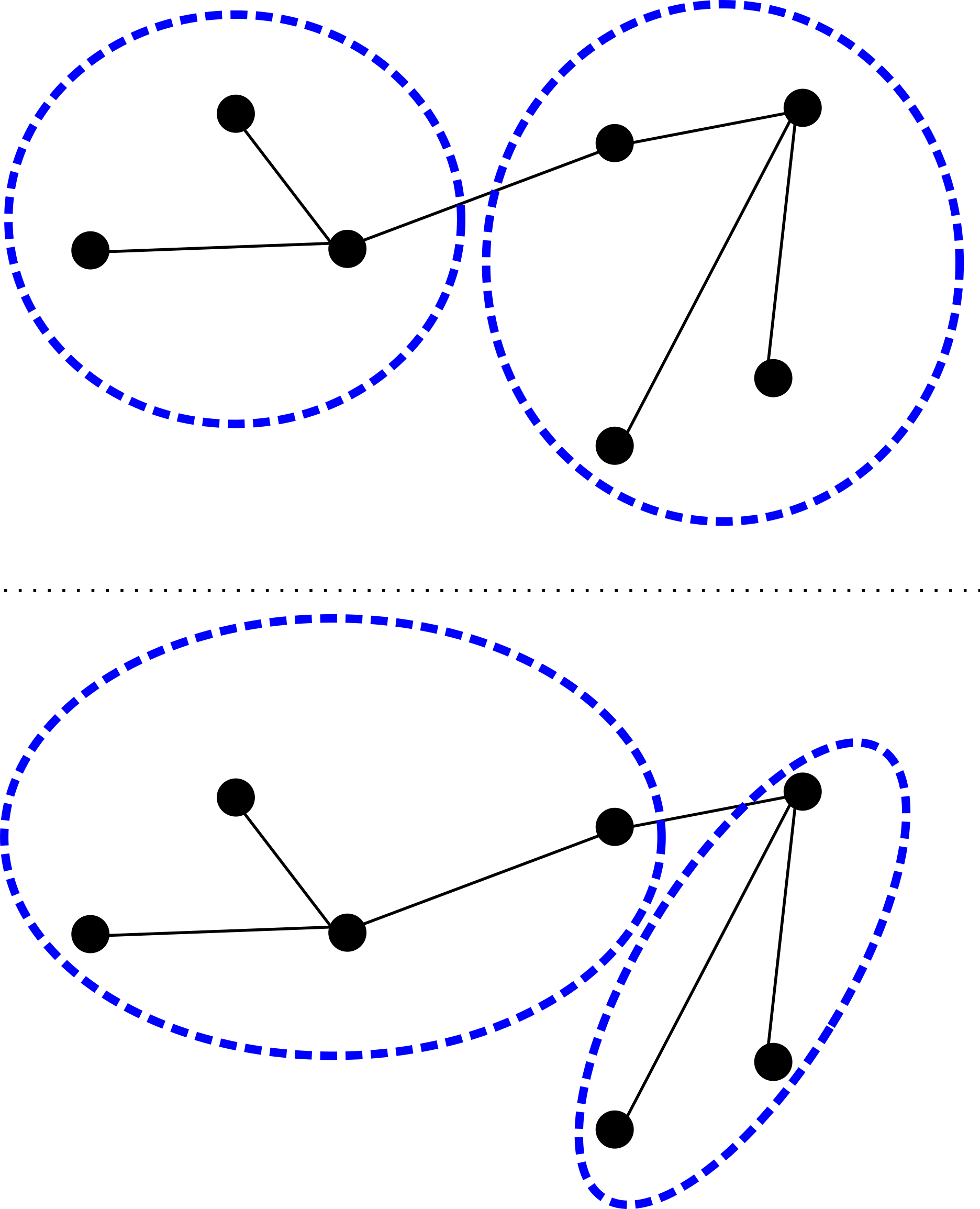
 , especially where repeatabilty is a concern.
, especially where repeatabilty is a concern.